- GOURICAHOME
- >
- コラム
- >
- KMMSと産学連携【後編】講義の目標や講義内容の詳細
- 採用コラム
2021.11.29
- データサイエンティスト
- キャリア
- 採用
- エンジニア
KMMSと産学連携【後編】講義の目標や講義内容の詳細

2017年3月より、コニカミノルタ株式会社は国立大学法人電気通信大学と産学連携をスタートし、2018年より、データサイエンス人材としてインターン生の受け入れを実施しています。 また、この度大学側からオファーをいただき、弊社サービス「Go Insight」のシニアプロジェクトマネージャー清水隆史と、データサイエンティストの淺田晃佑が、「データアントプレナーフェロープログラム」の一つとして講義を行いましたので、その様子を二回に分けてご紹介します。後編である今回は、データアントプレナーフェロープログラムの実際の講義内容と講義に秘めた想いについて淺田にインタビューしました。
※データアントプレナーフェロープログラム(Data Entrepreneur Fellows Program: DEFP)とは 文部科学省 科学技術人材育成費補助事業 データ関連人材育成プログラム(Doctoral program for Data-Related Innovation Expert: D-DRIVE)の採択を受けた データアントレプレナーコンソーシアム(代表機関:国立大学法人電気通信大学)が開講する人材育成プログラムです。
電気通信大学にて、土曜日3コマ×4日間で1カリキュラムを実施。 学生・社会人を問わず、人工知能、IoT、ビッグデータ、サイバーセキュリティ及びその基礎となるデータサイエンスの分野において、特に向学心を有し本学の大学院レベルの講義を履修することを希望する方に対して、電気通信大学が定める高度技術研修制度に基づき選考の上、高度技術研修生「データアントレプレナーフェロー」として履修を認める制度です。
目次
プロフィール

コニカミノルタ株式会社
データサイエンティスト
淺田 晃佑
東京工業大学数学科卒業後、IT企業にて画像処理やIoTのwebアプリなどのシステム開発に従事。その後データサイエンティストに転身。金融向け予測モデル、自然言語処理関係のプロダクト開発に携わる。コニカミノルタに転籍後は数理スキルを活かし小売向け需要予測として時系列分析などを行っている。
今回の講義への想い

淺田
これまで登壇の経験は無かったので講師を担当することになった時には少し驚きました。
ただ、社内ではデータサイエンスチームの中でも、シニアデータサイエンティストというポジションで職務を行っていて、サイエンス面や理論面を強みとして持っていますので、今回大学側に求めていただいていた講義内容にも自身はマッチしていると考え、挑戦させていただくことにしました。
私は元SEですが、数学が好きなので、「ITの技術を生かしつつ、でも数学がしたい」という想いから、両方取り出来るデータサイエンスという新しい学問に行きつきました。
今、担当しているデータサイエンスの業務も、結構夢中になってやってしまうので、仕事ではありますが、給料を貰わなくてもやりたいくらいです。笑
データサイエンティストは実は文系の方も多く、例えば社会学専攻や、経済学、心理学も統計の学問なので、そういった色々なバックグラウンドの方が活躍出来るフィールドです。
今回の講義を受講された方は、初心者の方も多く、社会人の方は、データ分析を業務の中で活用したいという目的をもって、参加されている方が多かった印象です。
データサイエンスに興味を持ち、これからの研究や業務に活用してくださる方が、私の講義を通して一人でも増えてくだされば・・・という気持ちで、講義を行わせていただきました。
講義の目標
淺田
DEFPの様々なコースがある中で、「より実務に近い分析ができるようになる」というのが我々の目標でした。
マーケティングという領域で、「Go Insight(※)で得られたデータを使って、お客様が小売店でモノを買う/買わないを予測する統計や機械学習のモデルを理解し、作れるようになる」というのを目標に理論面を講義しており、実際にモデルを作る時に考えることや処理の仕方・お客様への提案の仕方も、KMMSの実務に近い形で出来たと思っています。
※ Go Insightはリアル店舗の天井カメラ画像からお客様の棚前行動を分析し、効果的なアクションに繋げる、弊社提供のコンサルティングサービス。
≫「Go Insight」の詳細はこちらから
昨年もKMMSのデータサイエンスチームに新卒社員が入社しましたが、その際に彼にお教えしたことと近しいですね。
講義では、データをKaggle (データ分析のコンペティションサービス)のInClassという機能を使って、そこにGo Insightのデータをアップロードして、モデルの精度を競い合ってもらうということを、課題としましたが、商品名はもちろん置き換えたものの、Go Insightでとった小売りの実データとかなり近いデータを講義で使用することにもこだわりました。
結果、講義の参加者からも、以下の通りお声を頂き嬉しかったです。
- 「身近なデータを使っていたので、イメージが沸きやすく、実際の商品を想定して自分の体験を以て議論が出来た」
- 「実ビジネスで使用しているデータを使わせていただけたことが良かった」
講義内容の詳細
1日目
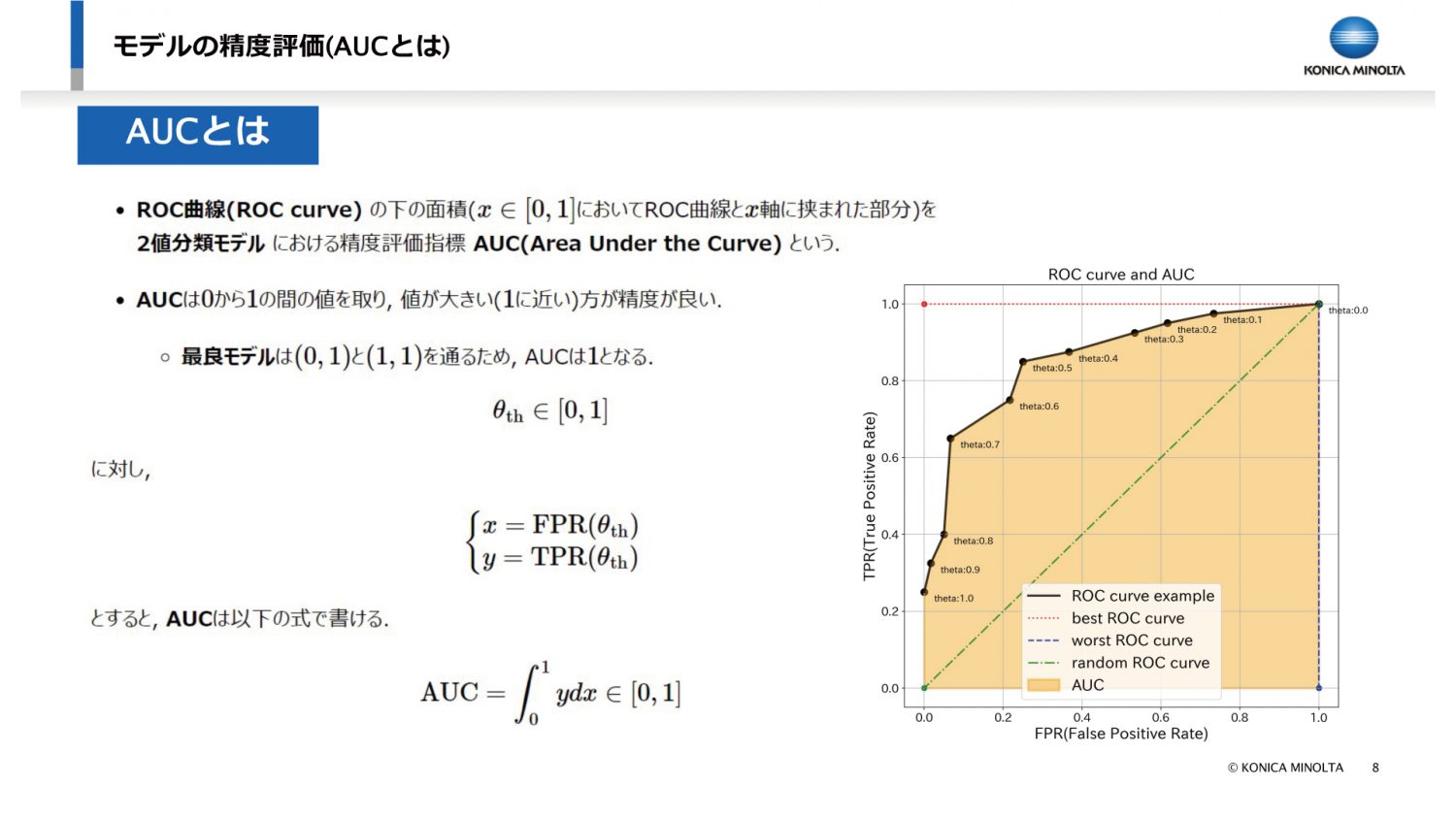
1日目は、機械学習や統計の数理モデルの全体感と、「精度評価」と「バリデーション」について講義しました。
適切なモデルを作成するためには、統計や機械学習といったモデルの良し悪しをどう評価したらいいかを明確にする必要があります。
そのために、まずは精度評価について学んでいただくことにしました。
今回は、より良い「商品を買う/買わないの二値分類モデル」を作成するためにAUC(Area Under the Curve)という評価指標を用いることにして、その理論の説明を行いました。
次に、バリデーション(Validation)の理論について講義を行いました。
クロスバリデーションに代表されるバリデーション法では、データを分割し、一部で学習して、一部で評価するといったことを考えます。より精度の高い機械学習モデルを作るためのハイパーパラメータチューニングや、正しくリーク(leakage)を起こさないように評価するためには、バリデーションの考え方が必要となってくるのです。
2日目
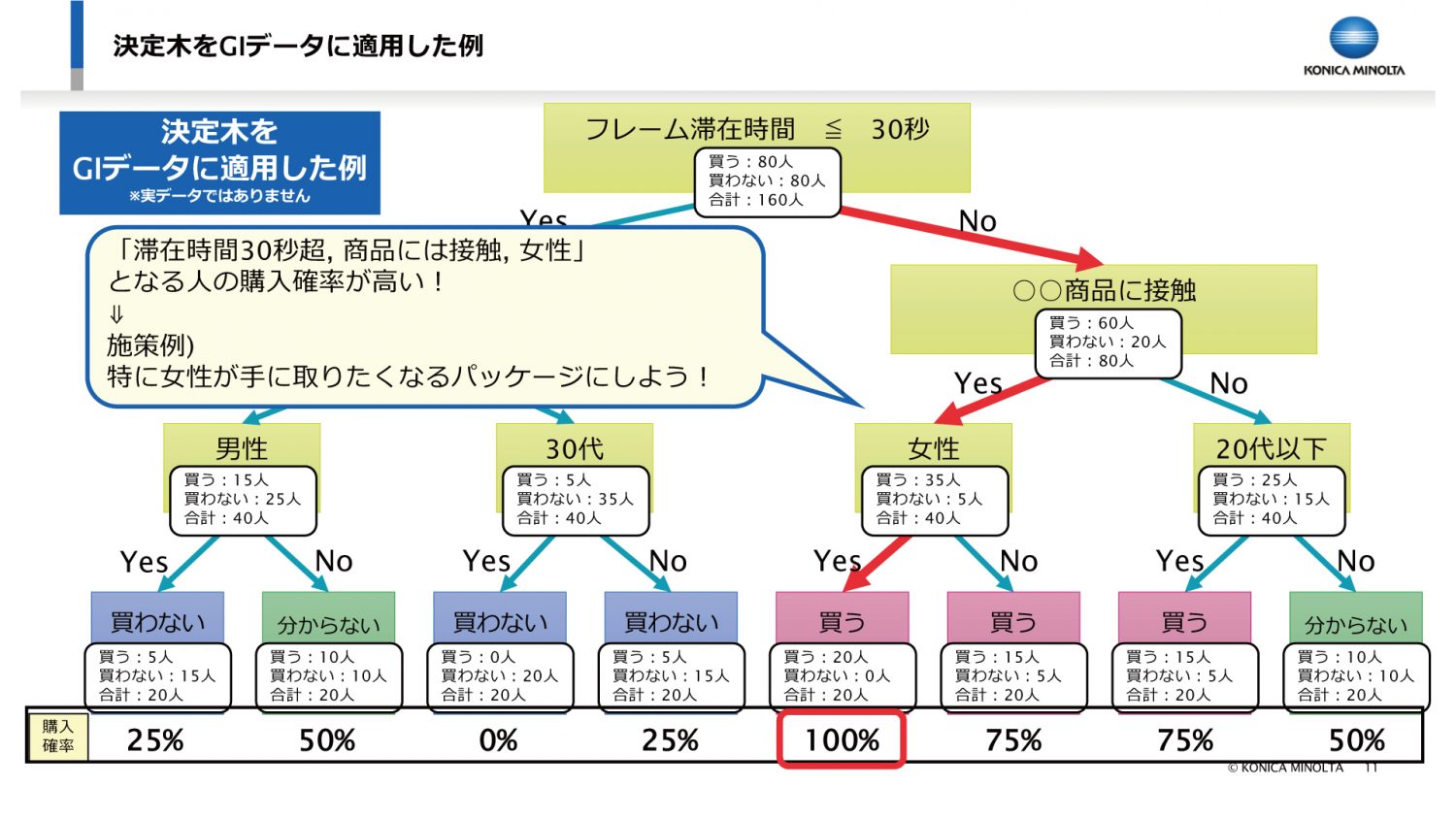
2日目は、買う/買わないの二値分類モデルを作っていく中での代表的なモデルとして、「決定木」と「ロジスティック回帰」の二つについて、どういうモデルなのかと、その理論についても説明をしました。
実務上注意すべきこととして、マーケティング領域だと特に、解釈性というのが重要になってくるので、単純に精度を上げれば良いという訳ではありません。
機械学習で買う/買わないを予測するモデルを作成したら、そのモデルが買う/買わないを予測するに至った理由や経緯をモデルから確認することができます。
例えば、決定木におけるfeature importanceやSHAP、ロジスティック回帰における偏回帰係数などがそれにあたります。
どうしたら作った決定木やロジスティック回帰のようなモデルの解釈できるか、また実際に実務でどのように使用されているのかを説明しました。
実際の業務ではその解釈結果を用いてクライアントに説明をしたり、施策に繋げる方法を検討しますので、そういった実務シーンを想定した講義を行いました。
3日目
2日目に説明した決定木やロジスティック回帰は基礎的なモデルなので、3日目はさらに応用的なモデル・手法について説明をしました。
アンサンブルという、基礎的なモデルをいくつか組み合わせてより複雑なモデルにするという手法があり、その代表的な手法としてバギングやブースティング、スタッキングについて説明を行いました。
特に、Kaggleでもよく使用され高い精度が得られる決定木系モデルとして、XGBoostやLightGBMなどのGBDTという手法を講義に盛り込みました。
4日目
最終日である4日目は、3日目までに学んだ技術活かしていただき、グループワークで作ったモデルや、どういう解釈したか、どのような施策提案できるかという課題について、参加者の皆さんに発表をいただきました。
講義を終えて

淺田
最後の受講生の皆さんの報告は、非常に素晴らしいものでした。
講義の課題も平日の夜などを使って作業されていて、質問が随時slackで来たりもしましたので、非常意欲の高い方々とご一緒させていただけたことを嬉しく思っています。
実務者・データサイエンティストとの私の想いとして、「ビジネスのことを考えているとはいえ、統計や機械学習を用いたデータ分析では、その理論をきちんと理解してないと誤った結論を導いてしまうことがあるので、ただネット上で検索したプログラムをコピーして使うのではなく、ある程度の理論を理解して使っていただきたい」とお伝えしました。
また、データサイエンティストの実務に活かしていただくために、分析結果をクライアント相手に分析内容を報告する際に大切なことや、実務で使えるプログラミングの小技なんかも、随所に織り交ぜてお話をさせていただきました。そういった話も受講生の方には「教科書には載っていないこと」として好評でした。
データサイエンスを楽しいと思ってくださる方が一人でも増えて、今後の仕事に役立ててくだされば・・・という私の当初の想いが実現し、少しでも社会貢献になれば嬉しく思います。





